Intel AMD 鲲鹏 海光 飞腾性能PK
前言
本文在sysbench、tpcc等实践场景下对多款CPU的性能进行对比,同时分析各款CPU的硬件指标,最后分析不同场景下的实际性能和核心参数的关系。
本文的姊妹篇:十年后数据库还是不敢拥抱NUMA? 主要讲述的是 同一块CPU的不同NUMA结构配置带来的几倍性能差异,这些性能差异原因也可以从本文最后时延测试数据得到印证,一起阅读效果更好。
性能定义
同一个平台下(X86、ARM是两个平台)编译好的程序可以认为他们的 指令 数是一样的,那么执行效率就是每个时钟周期所能执行的指令数量了。
执行指令数量第一取决的就是CPU主频了,但是目前主流CPU都是2.5G左右,另外就是单核下的并行度(多发射)以及多核,再就是分支预测等,这些基本归结到了访问内存的延时。
X86和ARM这两不同平台首先指令就不一样了,然后还有上面所说的主频、内存时延的差异
IPC的说明:
IPC: insns per cycle insn/cycles 也就是每个时钟周期能执行的指令数量,越大程序跑的越快
程序的执行时间 = 指令数/(主频*IPC) //单核下,多核的话再除以核数
参与比较的几款CPU参数
先来看看测试所用到的几款CPU的主要指标,大家关注下主频、各级cache大小、numa结构
Hygon 7280
Hygon 7280 就是AMD Zen架构,最大IPC能到5.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| 架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU: 128
在线 CPU 列表: 0-127
每个核的线程数: 2
每个座的核数: 32
座: 2
NUMA 节点: 8
厂商 ID: HygonGenuine
CPU 系列: 24
型号: 1
型号名称: Hygon C86 7280 32-core Processor
步进: 1
CPU MHz: 2194.586
BogoMIPS: 3999.63
虚拟化: AMD-V
L1d 缓存: 2 MiB
L1i 缓存: 4 MiB
L2 缓存: 32 MiB
L3 缓存: 128 MiB
NUMA 节点0 CPU: 0-7,64-71
NUMA 节点1 CPU: 8-15,72-79
NUMA 节点2 CPU: 16-23,80-87
NUMA 节点3 CPU: 24-31,88-95
NUMA 节点4 CPU: 32-39,96-103
NUMA 节点5 CPU: 40-47,104-111
NUMA 节点6 CPU: 48-55,112-119
NUMA 节点7 CPU: 56-63,120-127
|
AMD EPYC 7H12
AMD EPYC 7H12 64-Core(ECS,非物理机),最大IPC能到5.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
座: 2
NUMA 节点: 2
厂商 ID: AuthenticAMD
CPU 系列: 23
型号: 49
型号名称: AMD EPYC 7H12 64-Core Processor
步进: 0
CPU MHz: 2595.124
BogoMIPS: 5190.24
虚拟化: AMD-V
超管理器厂商: KVM
虚拟化类型: 完全
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 512K
L3 缓存: 16384K
NUMA 节点0 CPU: 0-31
NUMA 节点1 CPU: 32-63
|
Intel
这次对比测试用到了两块Intel CPU,分别是 8163、8269 。他们的信息如下,最大IPC 是4:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
Stepping: 4
CPU MHz: 2499.121
CPU max MHz: 3100.0000
CPU min MHz: 1000.0000
BogoMIPS: 4998.90
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-95
-----8269CY
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Stepping: 7
CPU MHz: 3200.000
CPU max MHz: 3800.0000
CPU min MHz: 1200.0000
BogoMIPS: 4998.89
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-25,52-77
NUMA node1 CPU(s): 26-51,78-103
|
鲲鹏920
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| [root@ARM 19:15 /root/lmbench3]
#numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
node 0 size: 192832 MB
node 0 free: 146830 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 193533 MB
node 1 free: 175354 MB
node 2 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 2 size: 193533 MB
node 2 free: 175718 MB
node 3 cpus: 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 3 size: 193532 MB
node 3 free: 183643 MB
node distances:
node 0 1 2 3
0: 10 12 20 22
1: 12 10 22 24
2: 20 22 10 12
3: 22 24 12 10
node 0 <------------ socket distance ------------> node 2
| (die distance) | (die distance)
node 1 node 3
#lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 1
Core(s) per socket: 48
Socket(s): 2
NUMA node(s): 4
Model: 0
CPU max MHz: 2600.0000
CPU min MHz: 200.0000
BogoMIPS: 200.00
L1d cache: 64K
L1i cache: 64K
L2 cache: 512K
L3 cache: 24576K //一个Die下24core共享24M L3,每个core 1MB
NUMA node0 CPU(s): 0-23
NUMA node1 CPU(s): 24-47
NUMA node2 CPU(s): 48-71
NUMA node3 CPU(s): 72-95
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm
|
飞腾2500
飞腾2500用nop去跑IPC的话,只能到1,但是跑其它代码能到2.33,理论值据说也是4但是我没跑到过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| #lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 16
Model: 3
BogoMIPS: 100.00
L1d cache: 32K
L1i cache: 32K
L2 cache: 2048K
L3 cache: 65536K
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
NUMA node4 CPU(s): 32-39
NUMA node5 CPU(s): 40-47
NUMA node6 CPU(s): 48-55
NUMA node7 CPU(s): 56-63
NUMA node8 CPU(s): 64-71
NUMA node9 CPU(s): 72-79
NUMA node10 CPU(s): 80-87
NUMA node11 CPU(s): 88-95
NUMA node12 CPU(s): 96-103
NUMA node13 CPU(s): 104-111
NUMA node14 CPU(s): 112-119
NUMA node15 CPU(s): 120-127
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
|
单核以及超线程计算Prime性能比较
测试命令,这个测试命令无论在哪个CPU下,用2个物理核用时都是一个物理核的一半,所以这个计算是可以完全并行的
1
| taskset -c 1 /usr/bin/sysbench --num-threads=1 --test=cpu --cpu-max-prime=50000 run //单核绑一个core; 2个thread就绑一对HT
|
测试结果为耗时,单位秒
| 单核 prime 50000 耗时 |
59秒 IPC 0.56 |
77秒 IPC 0.55 |
89秒 IPC 0.56; |
83 0.41 |
105秒 IPC 0.41 |
109秒 IPC 0.39 |
| HT prime 50000 耗时 |
57秒 IPC 0.31 |
74秒 IPC 0.29 |
87秒 IPC 0.29 |
48 0.35 |
60秒 IPC 0.36 |
74秒 IPC 0.29 |
从上面的测试结果来看,简单纯计算场景下 AMD/海光 的单核能力还是比较强的,但是超线程完全不给力(数据库场景超线程就给力了);而Intel的超线程非常给力,一对超线程能达到单物理core的1.8倍,并且从E5到8269更是好了不少。
ARM基本都没有超线程所有没有跑鲲鹏、飞腾。
计算Prime毕竟太简单,让我们来看看他们在数据库下的真实能力吧
对比MySQL sysbench和tpcc性能
MySQL 默认用5.7.34社区版,操作系统默认是centos,测试中所有mysqld都做了绑核,一样的压力配置尽量将CPU跑到100%, HT表示将mysqld绑定到一对HT核。
sysbench点查
测试命令类似如下:
1
| sysbench --test='/usr/share/doc/sysbench/tests/db/select.lua' --oltp_tables_count=1 --report-interval=1 --oltp-table-size=10000000 --mysql-port=3307 --mysql-db=sysbench_single --mysql-user=root --mysql-password='Bj6f9g96!@#' --max-requests=0 --oltp_skip_trx=on --oltp_auto_inc=on --oltp_range_size=5 --mysql-table-engine=innodb --rand-init=on --max-time=300 --mysql-host=x86.51 --num-threads=4 run
|
测试结果分别取QPS/IPC两个数据(测试中的差异AMD、Hygon CPU跑在CentOS7.9, intel CPU、Kunpeng 920 跑在AliOS上, xdb表示用集团的xdb替换社区的MySQL Server, 麒麟是国产OS):
| 单核 |
24674 0.54 |
13441 0.46 |
10236 0.39 |
28208 0.75 |
25474 0.84 |
29376 0.89 |
9694 0.49 |
8301 0.46 |
3602 0.53 |
| 一对HT |
36157 0.42 |
21747 0.38 |
19417 0.37 |
36754 0.49 |
35894 0.6 |
40601 0.65 |
无HT |
无HT |
无HT |
| 4物理核 |
94132 0.52 |
49822 0.46 |
38033 0.37 |
90434 0.69 350% |
87254 0.73 |
106472 0.83 |
34686 0.42 |
28407 0.39 |
14232 0.53 |
| 16物理核 |
325409 0.48 |
171630 0.38 |
134980 0.34 |
371718 0.69 1500% |
332967 0.72 |
446290 0.85 //16核比4核好! |
116122 0.35 |
94697 0.33 |
59199 0.6 8core:31210 0.59 |
| 32物理核 |
542192 0.43 |
298716 0.37 |
255586 0.33 |
642548 0.64 2700% |
588318 0.67 |
598637 0.81 CPU 2400% |
228601 0.36 |
177424 0.32 |
114020 0.65 |
说明:麒麟OS下CPU很难跑满,大致能跑到90%-95%左右,麒麟上装的社区版MySQL-5.7.29;飞腾要特别注意mysqld所在socket,同时以上飞腾数据都是走--socket压测锁的,32core走网络压测QPS为:99496(15%的网络损耗)
从上面的结果先看单物理核能力ARM 和 X86之间的差异还是很明显的
tpcc 1000仓
测试结果(测试中Hygon 7280分别跑在CentOS7.9和麒麟上, 鲲鹏/intel CPU 跑在AliOS、麒麟是国产OS):
tpcc测试数据,结果为1000仓,tpmC (NewOrders) ,未标注CPU 则为跑满了
| 1物理核 |
12392 |
9902 |
4706 |
7011 |
6619 |
4653 |
| 一对HT |
17892 |
15324 |
8950 |
11778 |
无HT |
无HT |
| 4物理核 |
51525 |
40877 |
19387 380% |
30046 |
23959 |
20101 |
| 8物理核 |
100792 |
81799 |
39664 750% |
60086 |
42368 |
40572 |
| 16物理核 |
160798 抖动 |
140488 CPU抖动 |
75013 1400% |
106419 1300-1550% |
70581 1200% |
79844 |
| 24物理核 |
188051 |
164757 1600-2100% |
100841 1800-2000% |
130815 1600-2100% |
88204 1600% |
115355 |
| 32物理核 |
195292 |
185171 2000-2500% |
116071 1900-2400% |
142746 1800-2400% |
102089 1900% |
143567 |
| 48物理核 |
19969l |
195730 2100-2600% |
128188 2100-2800% |
149782 2000-2700% |
116374 2500% |
206055 4500% |
测试过程CPU均跑满(未跑满的话会标注出来),IPC跑不起来性能就必然低,超线程虽然总性能好了但是会导致IPC降低(参考前面的公式)。可以看到对本来IPC比较低的场景,启用超线程后一般对性能会提升更大一些。
tpcc并发到一定程度后主要是锁导致性能上不去,所以超多核意义不大,可以做分库分表搞多个mysqld实例
比如在Hygon 7280 2.1GHz 麒麟上起两个MySQLD实例,每个实例各绑定32物理core,性能刚好翻倍:
32核的时候对比下MySQL 社区版在Hygon7280和Intel 8163下的表现,IPC的差异还是很明显的,基本和TPS差异一致:
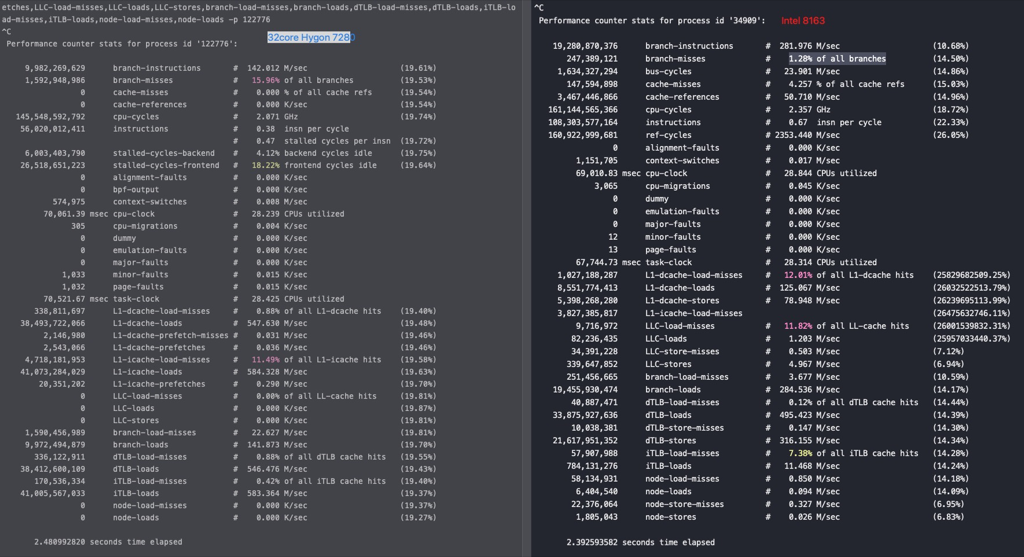
从sysbench和tpcc测试结果来看AMD和Intel差异不大,ARM和X86差异比较大,国产CPU还有很大的进步空间。就像前面所说抛开指令集的差异,主频差不多,内存管够为什么还有这么大的性能差别呢?
三款CPU的性能指标
下面让我们回到硬件本身的数据来看这个问题
先记住这个图,描述的是CPU访问寄存器、L1 cache、L2 cache等延时,关键记住他们的差异
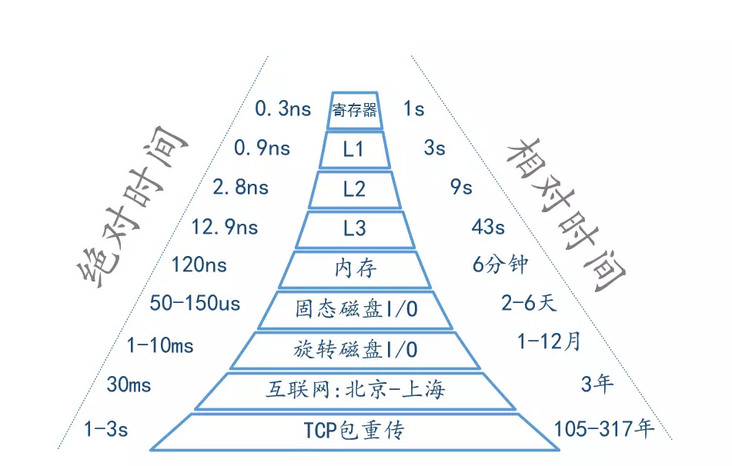
接下来用lmbench来测试各个机器的内存延时
stream主要用于测试带宽,对应的时延是在带宽跑满情况下的带宽。
lat_mem_rd用来测试操作不同数据大小的时延。
飞腾2500
用stream测试带宽和latency,可以看到带宽随着numa距离不断减少、对应的latency不断增加,到最近的numa node有10%的损耗,这个损耗和numactl给出的距离完全一致。跨socket访问内存latency是node内的3倍,带宽是三分之一,但是socket1性能和socket0性能完全一致。从这个延时来看如果要是跑一个32core的实例性能一定不会太好,并且抖动剧烈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| time for i in $(seq 7 8 128); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done
#numactl -C 7 -m 0 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 2.84 nanoseconds
STREAM copy bandwidth: 5638.21 MB/sec
STREAM scale latency: 2.72 nanoseconds
STREAM scale bandwidth: 5885.97 MB/sec
STREAM add latency: 2.26 nanoseconds
STREAM add bandwidth: 10615.13 MB/sec
STREAM triad latency: 4.53 nanoseconds
STREAM triad bandwidth: 5297.93 MB/sec
#numactl -C 7 -m 1 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.16 nanoseconds
STREAM copy bandwidth: 5058.71 MB/sec
STREAM scale latency: 3.15 nanoseconds
STREAM scale bandwidth: 5074.78 MB/sec
STREAM add latency: 2.35 nanoseconds
STREAM add bandwidth: 10197.36 MB/sec
STREAM triad latency: 5.12 nanoseconds
STREAM triad bandwidth: 4686.37 MB/sec
#numactl -C 7 -m 2 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.85 nanoseconds
STREAM copy bandwidth: 4150.98 MB/sec
STREAM scale latency: 3.95 nanoseconds
STREAM scale bandwidth: 4054.30 MB/sec
STREAM add latency: 2.64 nanoseconds
STREAM add bandwidth: 9100.12 MB/sec
STREAM triad latency: 6.39 nanoseconds
STREAM triad bandwidth: 3757.70 MB/sec
#numactl -C 7 -m 3 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.69 nanoseconds
STREAM copy bandwidth: 4340.24 MB/sec
STREAM scale latency: 3.62 nanoseconds
STREAM scale bandwidth: 4422.18 MB/sec
STREAM add latency: 2.47 nanoseconds
STREAM add bandwidth: 9704.82 MB/sec
STREAM triad latency: 5.74 nanoseconds
STREAM triad bandwidth: 4177.85 MB/sec
[root@101a05001.cloud.a05.am11 /root/lmbench3]
#numactl -C 7 -m 7 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.95 nanoseconds
STREAM copy bandwidth: 4051.51 MB/sec
STREAM scale latency: 3.94 nanoseconds
STREAM scale bandwidth: 4060.63 MB/sec
STREAM add latency: 2.54 nanoseconds
STREAM add bandwidth: 9434.51 MB/sec
STREAM triad latency: 6.13 nanoseconds
STREAM triad bandwidth: 3913.36 MB/sec
[root@101a05001.cloud.a05.am11 /root/lmbench3]
#numactl -C 7 -m 10 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 8.80 nanoseconds
STREAM copy bandwidth: 1817.78 MB/sec
STREAM scale latency: 8.59 nanoseconds
STREAM scale bandwidth: 1861.65 MB/sec
STREAM add latency: 5.55 nanoseconds
STREAM add bandwidth: 4320.68 MB/sec
STREAM triad latency: 13.94 nanoseconds
STREAM triad bandwidth: 1721.76 MB/sec
[root@101a05001.cloud.a05.am11 /root/lmbench3]
#numactl -C 7 -m 11 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 9.27 nanoseconds
STREAM copy bandwidth: 1726.52 MB/sec
STREAM scale latency: 9.31 nanoseconds
STREAM scale bandwidth: 1718.10 MB/sec
STREAM add latency: 5.65 nanoseconds
STREAM add bandwidth: 4250.89 MB/sec
STREAM triad latency: 14.09 nanoseconds
STREAM triad bandwidth: 1703.66 MB/sec
//在另外一个socket上测试本numa,和node0性能完全一致
[root@101a0500 /root/lmbench3]
#numactl -C 88 -m 11 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 2.93 nanoseconds
STREAM copy bandwidth: 5454.67 MB/sec
STREAM scale latency: 2.96 nanoseconds
STREAM scale bandwidth: 5400.03 MB/sec
STREAM add latency: 2.28 nanoseconds
STREAM add bandwidth: 10543.42 MB/sec
STREAM triad latency: 4.52 nanoseconds
STREAM triad bandwidth: 5308.40 MB/sec
[root@101a0500 /root/lmbench3]
#numactl -C 7 -m 15 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 8.73 nanoseconds
STREAM copy bandwidth: 1831.77 MB/sec
STREAM scale latency: 8.81 nanoseconds
STREAM scale bandwidth: 1815.13 MB/sec
STREAM add latency: 5.63 nanoseconds
STREAM add bandwidth: 4265.21 MB/sec
STREAM triad latency: 13.09 nanoseconds
STREAM triad bandwidth: 1833.68 MB/sec
|
Lat_mem_rd 用cpu7访问node0和node15对比结果,随着数据的加大,延时在加大,64M时能有3倍差距,和上面测试一致
下图 第一列 表示读写数据的大小(单位M),第二列表示访问延时(单位纳秒),一般可以看到在L1/L2/L3 cache大小的地方延时会有跳跃,远超过L3大小后,延时就是内存延时了
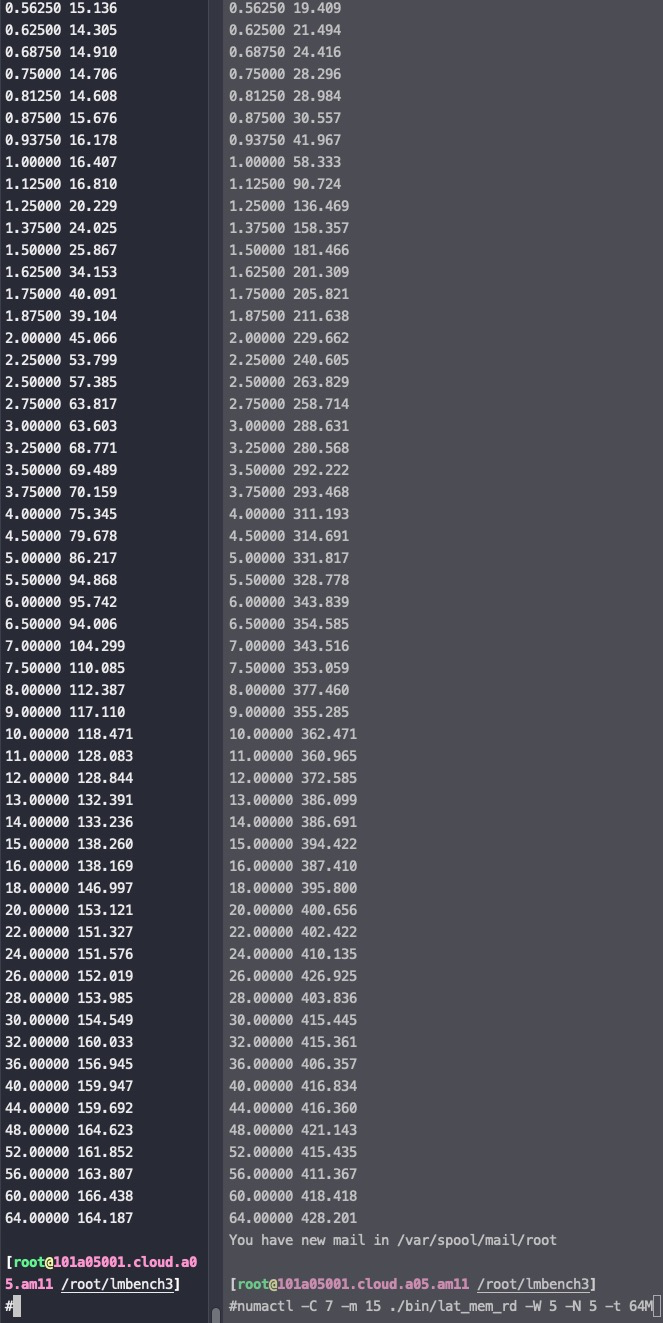
测试命令如下
1
| numactl -C 7 -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M //-C 7 cpu 7, -m 0 node0, -W 热身 -t stride
|
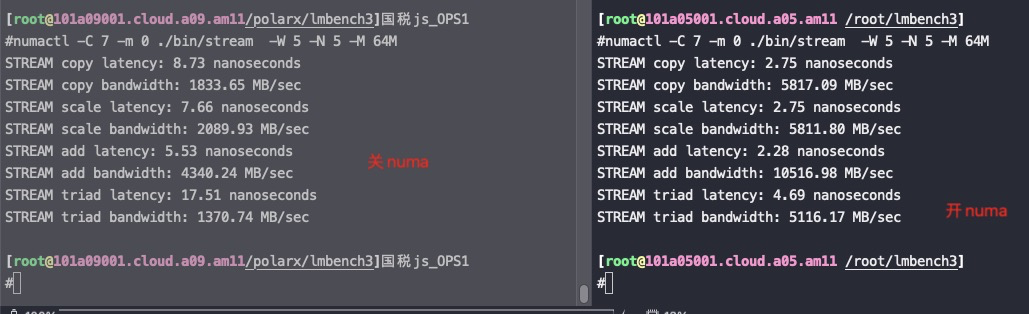
同样的机型,开关numa的测试结果,关numa 时延、带宽都差了几倍,所以一定要开NUMA
鲲鹏920
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #for i in $(seq 0 15); do echo core:$i; numactl -N $i -m 7 ./bin/stream -W 5 -N 5 -M 64M; done
STREAM copy latency: 1.84 nanoseconds
STREAM copy bandwidth: 8700.75 MB/sec
STREAM scale latency: 1.86 nanoseconds
STREAM scale bandwidth: 8623.60 MB/sec
STREAM add latency: 2.18 nanoseconds
STREAM add bandwidth: 10987.04 MB/sec
STREAM triad latency: 3.03 nanoseconds
STREAM triad bandwidth: 7926.87 MB/sec
#numactl -C 7 -m 1 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 2.05 nanoseconds
STREAM copy bandwidth: 7802.45 MB/sec
STREAM scale latency: 2.08 nanoseconds
STREAM scale bandwidth: 7681.87 MB/sec
STREAM add latency: 2.19 nanoseconds
STREAM add bandwidth: 10954.76 MB/sec
STREAM triad latency: 3.17 nanoseconds
STREAM triad bandwidth: 7559.86 MB/sec
#numactl -C 7 -m 2 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.51 nanoseconds
STREAM copy bandwidth: 4556.86 MB/sec
STREAM scale latency: 3.58 nanoseconds
STREAM scale bandwidth: 4463.66 MB/sec
STREAM add latency: 2.71 nanoseconds
STREAM add bandwidth: 8869.79 MB/sec
STREAM triad latency: 5.92 nanoseconds
STREAM triad bandwidth: 4057.12 MB/sec
[root@ARM 19:14 /root/lmbench3]
#numactl -C 7 -m 3 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 3.94 nanoseconds
STREAM copy bandwidth: 4064.25 MB/sec
STREAM scale latency: 3.82 nanoseconds
STREAM scale bandwidth: 4188.67 MB/sec
STREAM add latency: 2.86 nanoseconds
STREAM add bandwidth: 8390.70 MB/sec
STREAM triad latency: 4.78 nanoseconds
STREAM triad bandwidth: 5024.25 MB/sec
#numactl -C 24 -m 3 ./bin/stream -W 5 -N 5 -M 64M
STREAM copy latency: 4.10 nanoseconds
STREAM copy bandwidth: 3904.63 MB/sec
STREAM scale latency: 4.03 nanoseconds
STREAM scale bandwidth: 3969.41 MB/sec
STREAM add latency: 3.07 nanoseconds
STREAM add bandwidth: 7816.08 MB/sec
STREAM triad latency: 5.06 nanoseconds
STREAM triad bandwidth: 4738.66 MB/sec
|
海光7280
可以看到跨numa(一个numa也就是一个socket,等同于跨socket)RT从1.5上升到2.5,这个数据比鲲鹏920要好很多。
这里还会测试同一块CPU设置不同数量的numa node对性能的影响,所以接下来的测试会列出numa node数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| [root@hygon8 14:32 /root/lmbench-master]
#lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU: 128
在线 CPU 列表: 0-127
每个核的线程数: 2
每个座的核数: 32
座: 2
NUMA 节点: 8
厂商 ID: HygonGenuine
CPU 系列: 24
型号: 1
型号名称: Hygon C86 7280 32-core Processor
步进: 1
CPU MHz: 2194.586
BogoMIPS: 3999.63
虚拟化: AMD-V
L1d 缓存: 2 MiB
L1i 缓存: 4 MiB
L2 缓存: 32 MiB
L3 缓存: 128 MiB
NUMA 节点0 CPU: 0-7,64-71
NUMA 节点1 CPU: 8-15,72-79
NUMA 节点2 CPU: 16-23,80-87
NUMA 节点3 CPU: 24-31,88-95
NUMA 节点4 CPU: 32-39,96-103
NUMA 节点5 CPU: 40-47,104-111
NUMA 节点6 CPU: 48-55,112-119
NUMA 节点7 CPU: 56-63,120-127
//可以看到7号core比15、23、31号core明显要快,就近访问node 0的内存,跨numa node(跨Die)没有内存交织分配
[root@hygon8 14:32 /root/lmbench-master]
#time for i in $(seq 7 8 64); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done
7
STREAM copy latency: 1.38 nanoseconds
STREAM copy bandwidth: 11559.53 MB/sec
STREAM scale latency: 1.16 nanoseconds
STREAM scale bandwidth: 13815.87 MB/sec
STREAM add latency: 1.40 nanoseconds
STREAM add bandwidth: 17145.85 MB/sec
STREAM triad latency: 1.44 nanoseconds
STREAM triad bandwidth: 16637.18 MB/sec
15
STREAM copy latency: 1.67 nanoseconds
STREAM copy bandwidth: 9591.77 MB/sec
STREAM scale latency: 1.56 nanoseconds
STREAM scale bandwidth: 10242.50 MB/sec
STREAM add latency: 1.45 nanoseconds
STREAM add bandwidth: 16581.00 MB/sec
STREAM triad latency: 2.00 nanoseconds
STREAM triad bandwidth: 12028.83 MB/sec
23
STREAM copy latency: 1.65 nanoseconds
STREAM copy bandwidth: 9701.49 MB/sec
STREAM scale latency: 1.53 nanoseconds
STREAM scale bandwidth: 10427.98 MB/sec
STREAM add latency: 1.42 nanoseconds
STREAM add bandwidth: 16846.10 MB/sec
STREAM triad latency: 1.97 nanoseconds
STREAM triad bandwidth: 12189.72 MB/sec
31
STREAM copy latency: 1.64 nanoseconds
STREAM copy bandwidth: 9742.86 MB/sec
STREAM scale latency: 1.52 nanoseconds
STREAM scale bandwidth: 10510.80 MB/sec
STREAM add latency: 1.45 nanoseconds
STREAM add bandwidth: 16559.86 MB/sec
STREAM triad latency: 1.92 nanoseconds
STREAM triad bandwidth: 12490.01 MB/sec
39
STREAM copy latency: 2.55 nanoseconds
STREAM copy bandwidth: 6286.25 MB/sec
STREAM scale latency: 2.51 nanoseconds
STREAM scale bandwidth: 6383.11 MB/sec
STREAM add latency: 1.76 nanoseconds
STREAM add bandwidth: 13660.83 MB/sec
STREAM triad latency: 3.68 nanoseconds
STREAM triad bandwidth: 6523.02 MB/sec
|
如果这种芯片在bios里设置Die interleaving,4块die当成一个numa node吐出来给OS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| #lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU: 128
在线 CPU 列表: 0-127
每个核的线程数: 2
每个座的核数: 32
座: 2
NUMA 节点: 2
厂商 ID: HygonGenuine
CPU 系列: 24
型号: 1
型号名称: Hygon C86 7280 32-core Processor
步进: 1
CPU MHz: 2108.234
BogoMIPS: 3999.45
虚拟化: AMD-V
L1d 缓存: 2 MiB
L1i 缓存: 4 MiB
L2 缓存: 32 MiB
L3 缓存: 128 MiB
//注意这里bios配置了Die Interleaving Enable
//表示每路内多个Die内存交织分配,这样整个一个socket就是一个大Die
NUMA 节点0 CPU: 0-31,64-95
NUMA 节点1 CPU: 32-63,96-127
//enable die interleaving 后继续streaming测试
//最终测试结果表现就是7/15/23/31 core性能一致,因为默认一个numa内内存交织分配
//可以看到同一路下的四个die内存交织访问,所以4个node内存延时一样了(被平均),都不如8node就近快
[root@hygon3 16:09 /root/lmbench-master]
#time for i in $(seq 7 8 64); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done
7
STREAM copy latency: 1.48 nanoseconds
STREAM copy bandwidth: 10782.58 MB/sec
STREAM scale latency: 1.20 nanoseconds
STREAM scale bandwidth: 13364.38 MB/sec
STREAM add latency: 1.46 nanoseconds
STREAM add bandwidth: 16408.32 MB/sec
STREAM triad latency: 1.53 nanoseconds
STREAM triad bandwidth: 15696.00 MB/sec
15
STREAM copy latency: 1.51 nanoseconds
STREAM copy bandwidth: 10601.25 MB/sec
STREAM scale latency: 1.24 nanoseconds
STREAM scale bandwidth: 12855.87 MB/sec
STREAM add latency: 1.46 nanoseconds
STREAM add bandwidth: 16382.42 MB/sec
STREAM triad latency: 1.53 nanoseconds
STREAM triad bandwidth: 15691.48 MB/sec
23
STREAM copy latency: 1.50 nanoseconds
STREAM copy bandwidth: 10700.61 MB/sec
STREAM scale latency: 1.27 nanoseconds
STREAM scale bandwidth: 12634.63 MB/sec
STREAM add latency: 1.47 nanoseconds
STREAM add bandwidth: 16370.67 MB/sec
STREAM triad latency: 1.55 nanoseconds
STREAM triad bandwidth: 15455.75 MB/sec
31
STREAM copy latency: 1.50 nanoseconds
STREAM copy bandwidth: 10637.39 MB/sec
STREAM scale latency: 1.25 nanoseconds
STREAM scale bandwidth: 12778.99 MB/sec
STREAM add latency: 1.46 nanoseconds
STREAM add bandwidth: 16420.65 MB/sec
STREAM triad latency: 1.61 nanoseconds
STREAM triad bandwidth: 14946.80 MB/sec
39
STREAM copy latency: 2.35 nanoseconds
STREAM copy bandwidth: 6807.09 MB/sec
STREAM scale latency: 2.32 nanoseconds
STREAM scale bandwidth: 6906.93 MB/sec
STREAM add latency: 1.63 nanoseconds
STREAM add bandwidth: 14729.23 MB/sec
STREAM triad latency: 3.36 nanoseconds
STREAM triad bandwidth: 7151.67 MB/sec
47
STREAM copy latency: 2.31 nanoseconds
STREAM copy bandwidth: 6938.47 MB/sec
|
intel 8269CY
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Stepping: 7
CPU MHz: 3200.000
CPU max MHz: 3800.0000
CPU min MHz: 1200.0000
BogoMIPS: 4998.89
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-25,52-77
NUMA node1 CPU(s): 26-51,78-103
[root@numaopen.cloud.et93 /home/ren/lmbench3]
#time for i in $(seq 0 8 51); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done
0
STREAM copy latency: 1.15 nanoseconds
STREAM copy bandwidth: 13941.80 MB/sec
STREAM scale latency: 1.16 nanoseconds
STREAM scale bandwidth: 13799.89 MB/sec
STREAM add latency: 1.31 nanoseconds
STREAM add bandwidth: 18318.23 MB/sec
STREAM triad latency: 1.56 nanoseconds
STREAM triad bandwidth: 15356.72 MB/sec
16
STREAM copy latency: 1.12 nanoseconds
STREAM copy bandwidth: 14293.68 MB/sec
STREAM scale latency: 1.13 nanoseconds
STREAM scale bandwidth: 14162.47 MB/sec
STREAM add latency: 1.31 nanoseconds
STREAM add bandwidth: 18293.27 MB/sec
STREAM triad latency: 1.53 nanoseconds
STREAM triad bandwidth: 15692.47 MB/sec
32
STREAM copy latency: 1.52 nanoseconds
STREAM copy bandwidth: 10551.71 MB/sec
STREAM scale latency: 1.52 nanoseconds
STREAM scale bandwidth: 10508.33 MB/sec
STREAM add latency: 1.38 nanoseconds
STREAM add bandwidth: 17363.22 MB/sec
STREAM triad latency: 2.00 nanoseconds
STREAM triad bandwidth: 12024.52 MB/sec
40
STREAM copy latency: 1.49 nanoseconds
STREAM copy bandwidth: 10758.50 MB/sec
STREAM scale latency: 1.50 nanoseconds
STREAM scale bandwidth: 10680.17 MB/sec
STREAM add latency: 1.34 nanoseconds
STREAM add bandwidth: 17948.34 MB/sec
STREAM triad latency: 1.98 nanoseconds
STREAM triad bandwidth: 12133.22 MB/sec
48
STREAM copy latency: 1.49 nanoseconds
STREAM copy bandwidth: 10736.56 MB/sec
STREAM scale latency: 1.50 nanoseconds
STREAM scale bandwidth: 10692.93 MB/sec
STREAM add latency: 1.34 nanoseconds
STREAM add bandwidth: 17902.85 MB/sec
STREAM triad latency: 1.96 nanoseconds
STREAM triad bandwidth: 12239.44 MB/sec
|
Intel(R) Xeon(R) CPU E5-2682 v4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| #time for i in $(seq 0 8 51); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done
0
STREAM copy latency: 1.59 nanoseconds
STREAM copy bandwidth: 10092.31 MB/sec
STREAM scale latency: 1.57 nanoseconds
STREAM scale bandwidth: 10169.16 MB/sec
STREAM add latency: 1.31 nanoseconds
STREAM add bandwidth: 18360.83 MB/sec
STREAM triad latency: 2.28 nanoseconds
STREAM triad bandwidth: 10503.81 MB/sec
8
STREAM copy latency: 1.55 nanoseconds
STREAM copy bandwidth: 10312.14 MB/sec
STREAM scale latency: 1.56 nanoseconds
STREAM scale bandwidth: 10283.70 MB/sec
STREAM add latency: 1.30 nanoseconds
STREAM add bandwidth: 18416.26 MB/sec
STREAM triad latency: 2.23 nanoseconds
STREAM triad bandwidth: 10777.08 MB/sec
16
STREAM copy latency: 2.02 nanoseconds
STREAM copy bandwidth: 7914.25 MB/sec
STREAM scale latency: 2.02 nanoseconds
STREAM scale bandwidth: 7919.85 MB/sec
STREAM add latency: 1.39 nanoseconds
STREAM add bandwidth: 17276.06 MB/sec
STREAM triad latency: 2.92 nanoseconds
STREAM triad bandwidth: 8231.18 MB/sec
24
STREAM copy latency: 1.99 nanoseconds
STREAM copy bandwidth: 8032.18 MB/sec
STREAM scale latency: 1.98 nanoseconds
STREAM scale bandwidth: 8061.12 MB/sec
STREAM add latency: 1.39 nanoseconds
STREAM add bandwidth: 17313.94 MB/sec
STREAM triad latency: 2.88 nanoseconds
STREAM triad bandwidth: 8318.93 MB/sec
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
Stepping: 1
CPU MHz: 2500.000
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 5000.06
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 40960K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
|
stream对比数据
总结下几个CPU用stream测试访问内存的RT以及抖动和带宽对比数据
| 申威3231(2numa node) |
7.09 |
8.75 |
2256.59 MB/sec |
1827.88 MB/sec |
| 飞腾2500(16 numa node) |
2.84 |
10.34 |
5638.21 MB/sec |
1546.68 MB/sec |
| 鲲鹏920(4 numa node) |
1.84 |
3.87 |
8700.75 MB/sec |
4131.81 MB/sec |
| 海光7280(8 numa node) |
1.38 |
2.58 |
11591.48 MB/sec |
6206.99 MB/sec |
| 海光5280(4 numa node) |
1.22 |
2.52 |
13166.34 MB/sec |
6357.71 MB/sec |
| Intel8269CY(2 numa node) |
1.12 |
1.52 |
14293.68 MB/sec |
10551.71 MB/sec |
| Intel E5-2682(2 numa node) |
1.58 |
2.02 |
10092.31 MB/sec |
7914.25 MB/sec |
从以上数据可以看出这5款CPU性能一款比一款好,飞腾2500慢的core上延时快到intel 8269的10倍了,平均延时5倍以上了。延时数据基本和单核上测试sysbench TPS一致。
lat_mem_rd对比数据
用不同的node上的core 跑lat_mem_rd测试访问node0内存的RT,只取最大64M的时延,时延和node距离完全一致,这里就不再列出测试原始数据了。
| 飞腾2500(16 numa node) |
core:0 149.976
core:8 168.805
core:16 191.415
core:24 178.283
core:32 170.814
core:40 185.699
core:48 212.281
core:56 202.479
core:64 426.176
core:72 444.367
core:80 465.894
core:88 452.245
core:96 448.352
core:104 460.603
core:112 485.989
core:120 490.402 |
| 鲲鹏920(4 numa node) |
core:0 117.323
core:24 135.337
core:48 197.782
core:72 219.416 |
| 海光7280(8 numa node) |
numa0 106.839
numa1 168.583
numa2 163.925
numa3 163.690
numa4 289.628
numa5 288.632
numa6 236.615
numa7 291.880
分割行
enabled die interleaving
core:0 153.005
core:16 152.458
core:32 272.057
core:48 269.441 |
| 海光5280(4 numa node) |
core:0 102.574
core:8 160.989
core:16 286.850
core:24 231.197 |
| Intel 8269CY(2 numa node) |
core:0 69.792
core:26 93.107 |
| 申威3231(2numa node) |
core:0 215.146
core:32 282.443 |
测试命令:
1
| for i in $(seq 0 8 127); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1
|
测试结果和numactl -H 看到的node distance完全一致,芯片厂家应该就是这样测试然后把这个延迟当做距离写进去了
最后用一张实际测试Inte E5 L1 、L2、L3的cache延时图来加深印象,可以看到在每级cache大小附近时延有个跳跃:
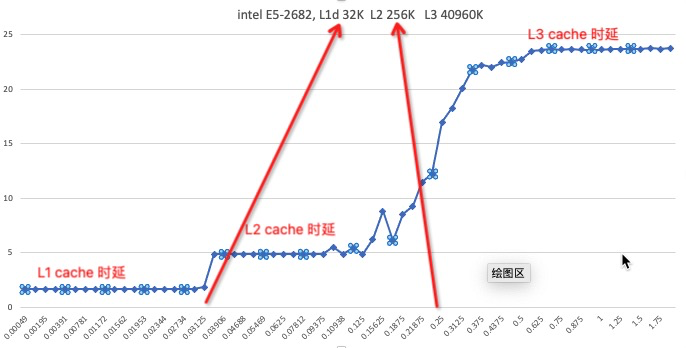
纵坐标是访问延时 纳秒,横坐标是cache大小 M,为什么上图没放内存延时,因为延时太大,放出来就把L1、L2的跳跃台阶压平了
结论
- X86比ARM性能要好
- AMD和Intel单核基本差别不大,Intel适合要求核多的大实例,AMD适合云上拆分售卖
- 国产CPU还有比较大的进步空间
- 性能上的差异在数据库场景下归因下来主要在CPU访问内存的时延上
- 跨Numa Node时延差异很大,一定要开NUMA 就近访问内存
- 数据库场景下大实例因为锁导致CPU很难跑满,建议 分库分表搞多个mysqld实例
如果你一定要知道一块CPU性能的话先看 内存延时 而不是 主频,各种CPU自家打榜一般都是简单计算场景,内存访问不多,但是实际业务中大部分时候又是高频访问内存的。
参考资料
十年后数据库还是不敢拥抱NUMA?
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
lmbench测试要考虑cache等
CPU的制造和概念
CPU 性能和Cache Line
Perf IPC以及CPU性能
CPU性能和CACHE